Training data
In order to be able to build your own models which allows to perform anonymization, you need to construct training data.
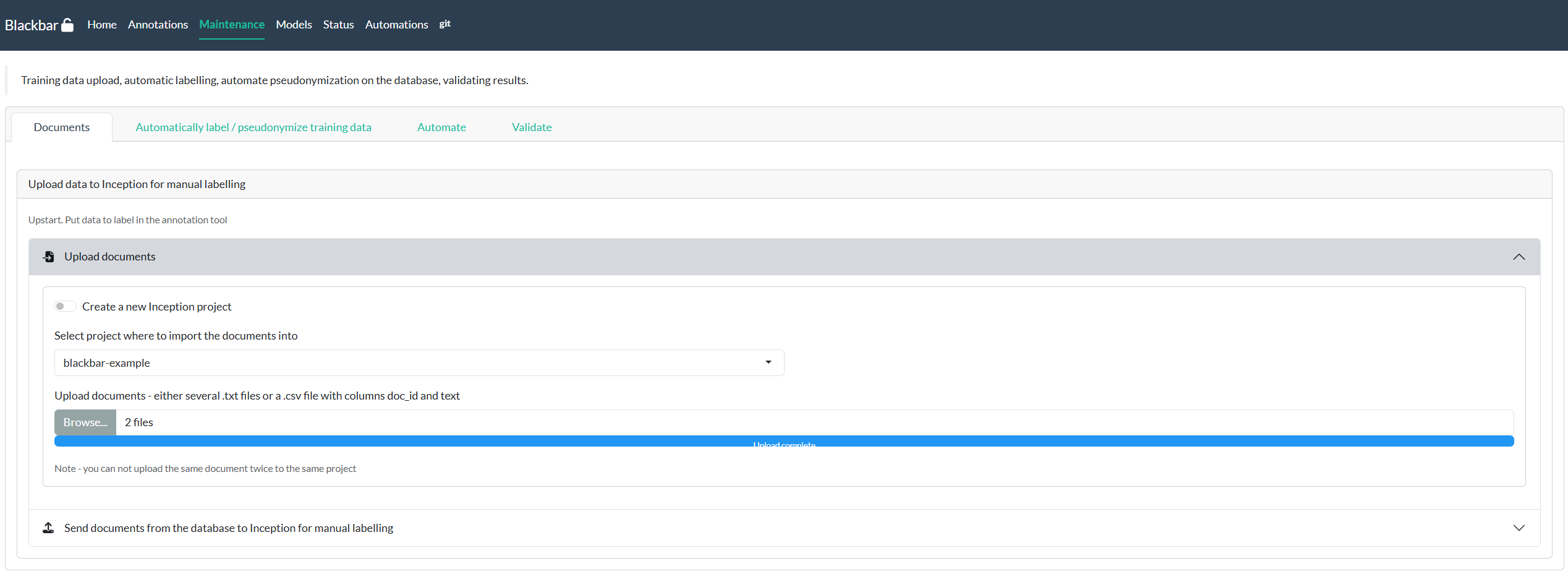
This step consists of manually labelling texts with existing categories. Project blackbar uses for this Inception - an open source semantic annotation tool which can be run locally for annotating text.
When you have launched the apps as explained in section apps, you will have launched the frontend of Inception which allows to
- Have a user interface where several persons can start annotating texts
- Perform annotations for text categorisation but as well allows to label chunks of texts for named entity recognition and even allows to tag semantic relationships between parts of the texts
- For project blackbar, the main annotation setup is the one for Named Entity Recognition with a specific set of tags tailored for clinical settings.
Create project
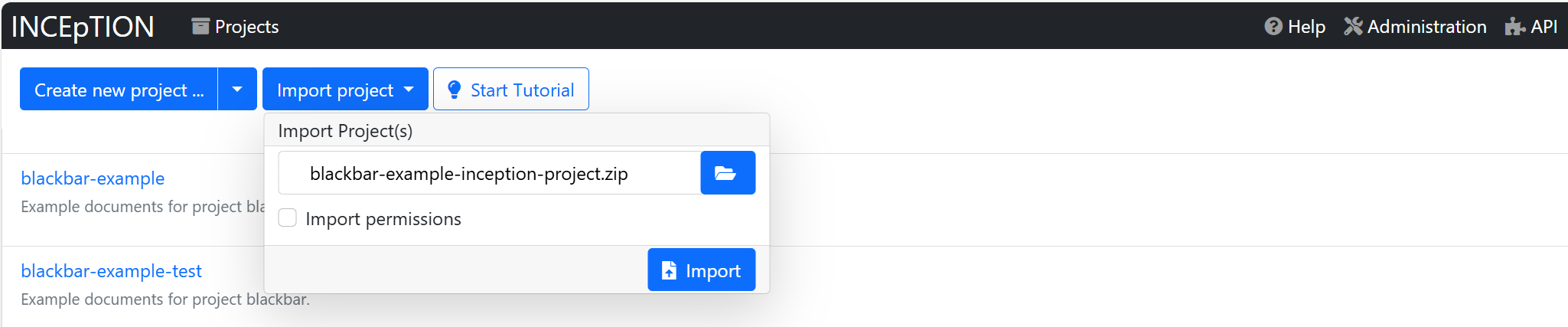
An existing project with no documents can be downloaded with this link: blackbar-example-inception-project.zip. You can import the project by going to the Inception frontend and select ‘Import project’.
Import documents
Once you have the project, you can navigate to the project Settings > Documents, import your own documents with format text lines and next start annotating the texts.
Annotating
The default project which allows to tag the following set entities and subsequent integration is done for the data extractiong, automation, anonymization and pseudonymization of new texts.
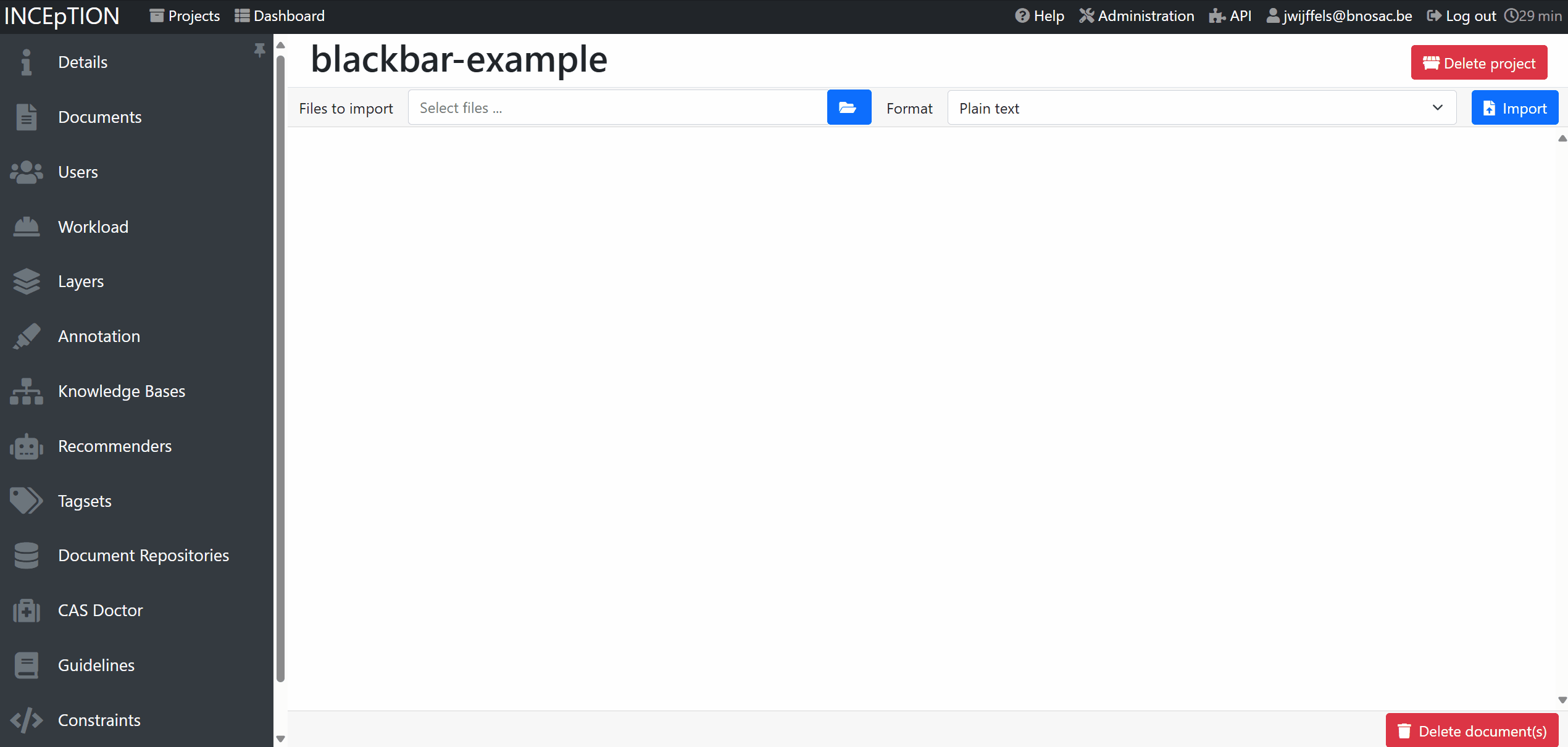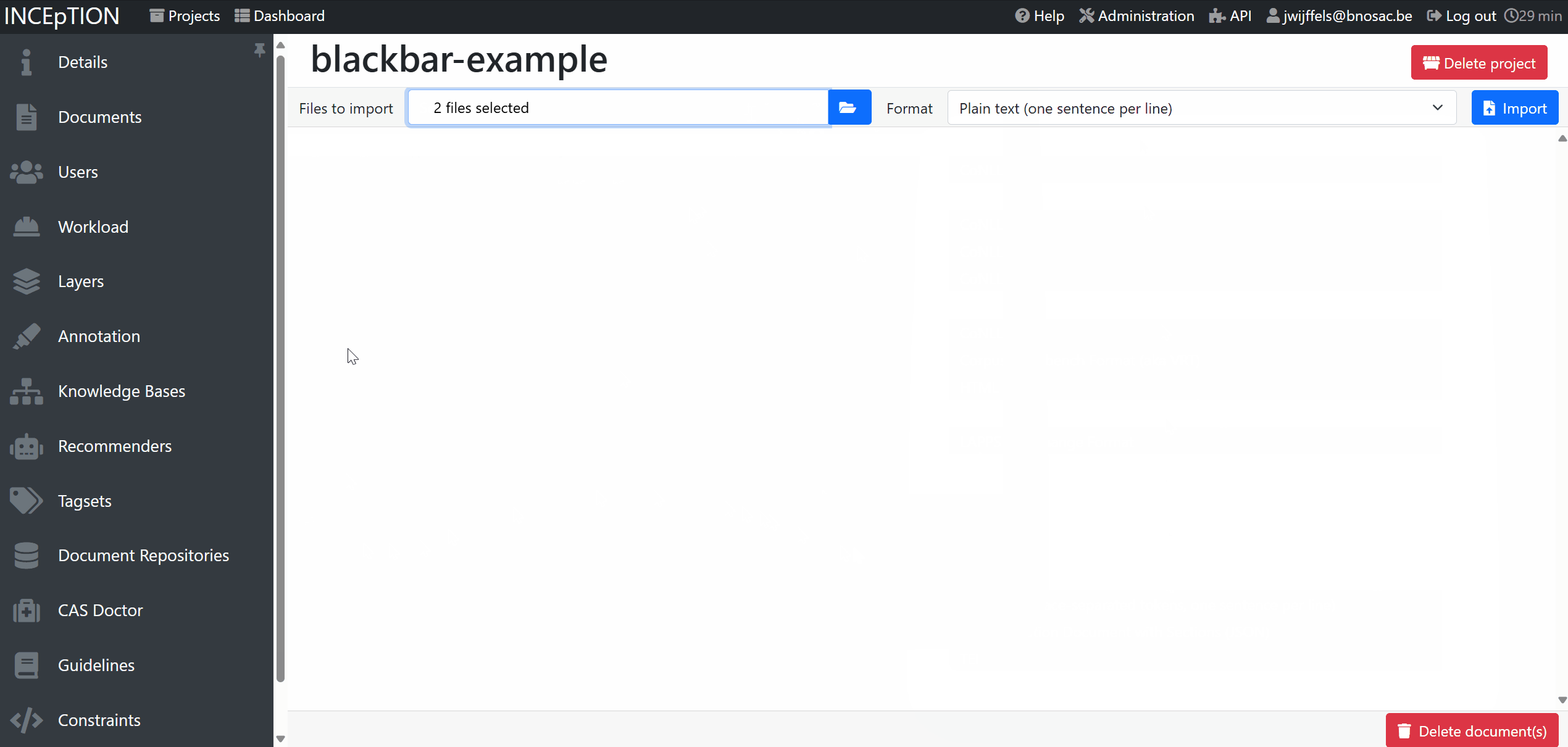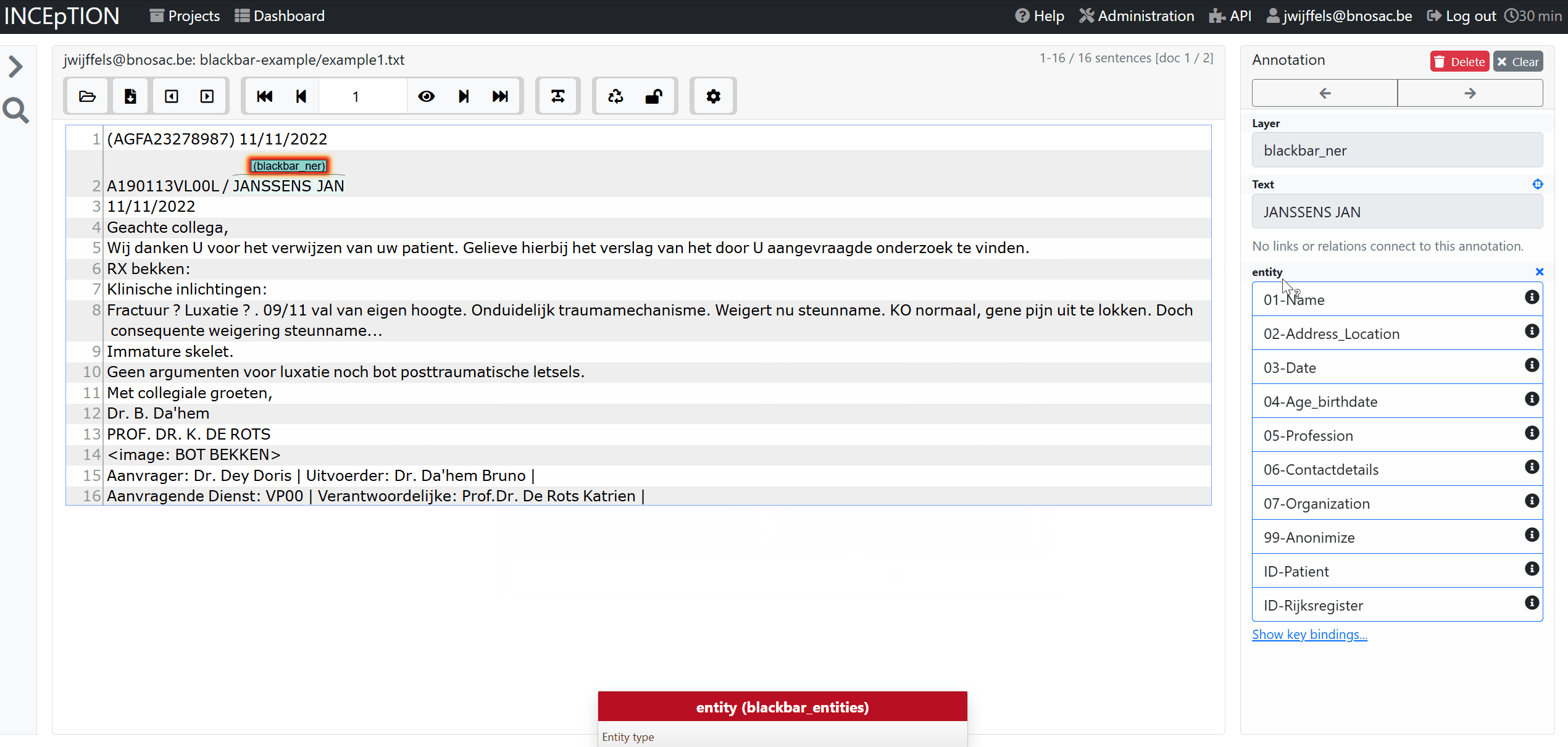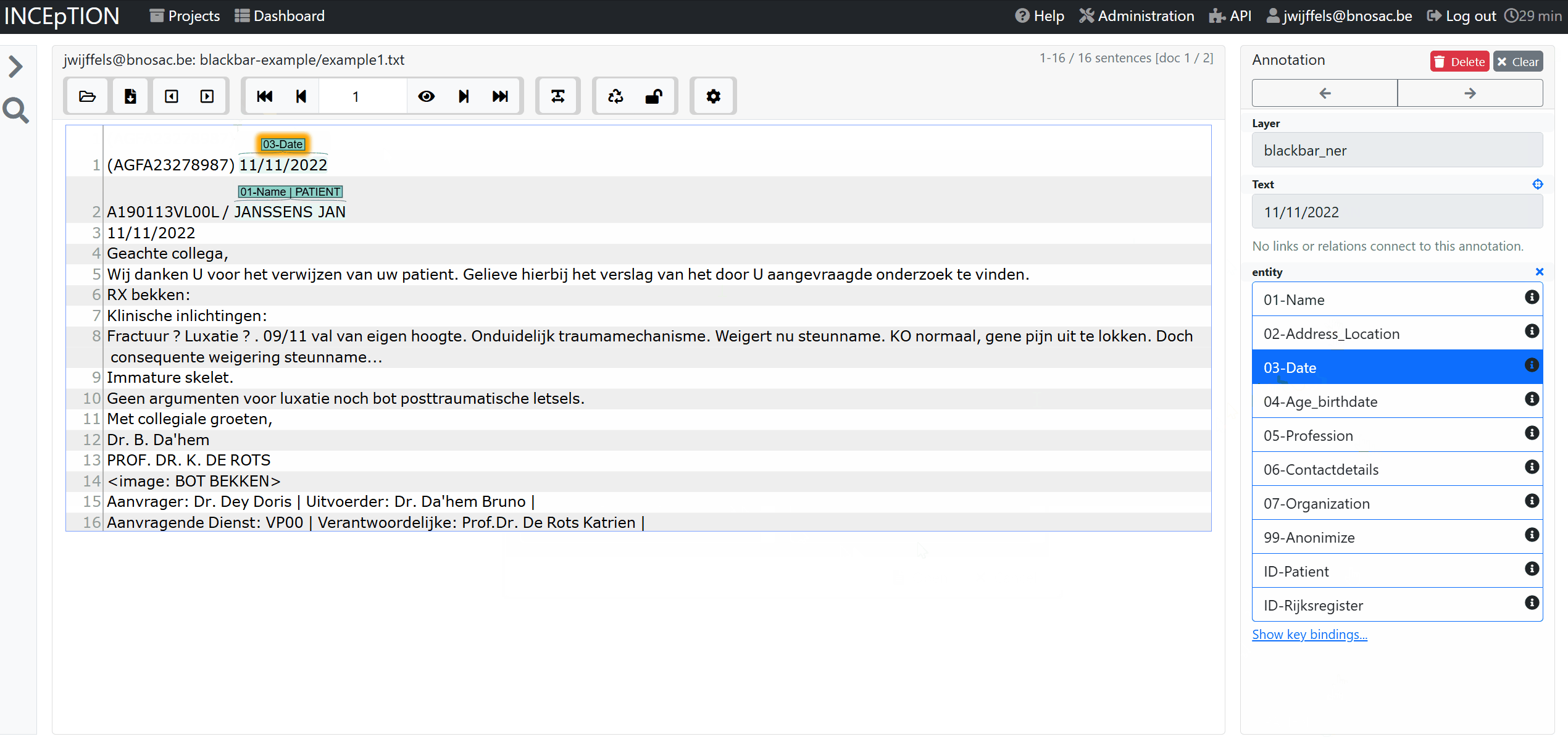
- 01-Name
- 02-Address_Location
- 03-Date
- 04-Age_birthdate
- 05-Profession
- 06-Contactdetails
- 07-Organization
- 99-Anonimize
- ID_Patient
- ID_Physician
- ID_Rijksregister
Where names and adresses (01-Name & 02-Address_Location) can be splitted up in either the name of the patient or the name of the doctor/physician/nurse/other.
The annotation is rather trivial, you select a part of the text where the entity is located and click on the entity. For names/addresses, you indicate if it is the address of the patient or of clinical personnel.
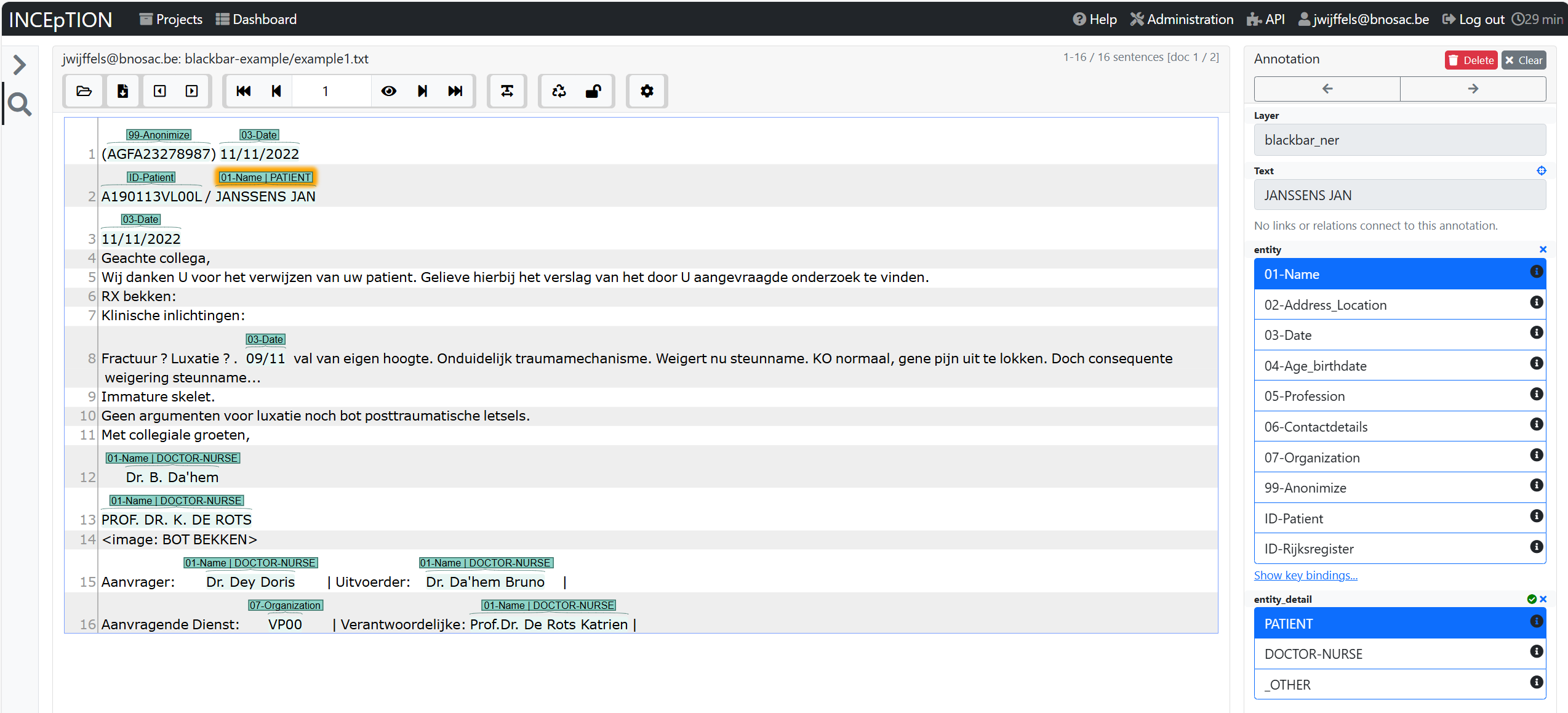
Once you’ve done annotating the document, press on the ‘Finish Document’ button
It is advised to have roughly 100 sets of documents annotated per type of document format which is used throughout your organization. Start from a copy of an empty project and upload the relevant documents in the project in the interface or using the API.
- In the section Annotation several persons can work at the same time and annotate documents.
- You can also of course split the work by project.
- By default the project is using Dynamic Assignment where each document should be annotated by only 1 person.
In the section Curation, a manager can look at annotation work and validate it such that the data can be used for training and optimizing a model.
Speedup
For speeding up the annotations, the following is done
- Each entity has been given a keyboard shortcut such that you can speed up the annotation by using these instead of the mouse.
- The project has as default a String Matcher recommender on such that for sections (e.g. names) which have already been annotated, it will show as recommended and you just need to validate it if correct
- It is possible to use an existing model in 2 ways to pre-annotate data
Examples to get you going
We are in the progress of making some video’s on how to use the apps
TODO - We are in the progress of making some video’s on how to use the apps
TODO - We are in the progress of making some video’s on how to use the apps
TODO - We are in the progress of making some video’s on how to use the apps
If you are unfamiliar with annotating in Inception or it is the first time you will use it, you can go to the slides at https://inception-project.github.io/publications/INCEpTION-20.x-Intro.pdf to have a more technical high-level overview.