docker pull registry.datatailor.be/blackbar-anonymization
docker run --env-file .env registry.datatailor.be/blackbar-anonymizationAutomation
The software has been set up in order to facilitate the automation of the anonymization and pseudonymization for large sets of records. Automated anonymization and pseudonymization is done through Prefect.
Prefect is a tool which allows you to schedule jobs which are mainly in Python. The exact timepoint when the jobs should run are maintained by the Prefect, while the anonymization and pseudonymization can be done locally on your own infrastructure. This makes sure your data stays local. Documentation on how to quickly have Prefect locally running is shown in section apps).
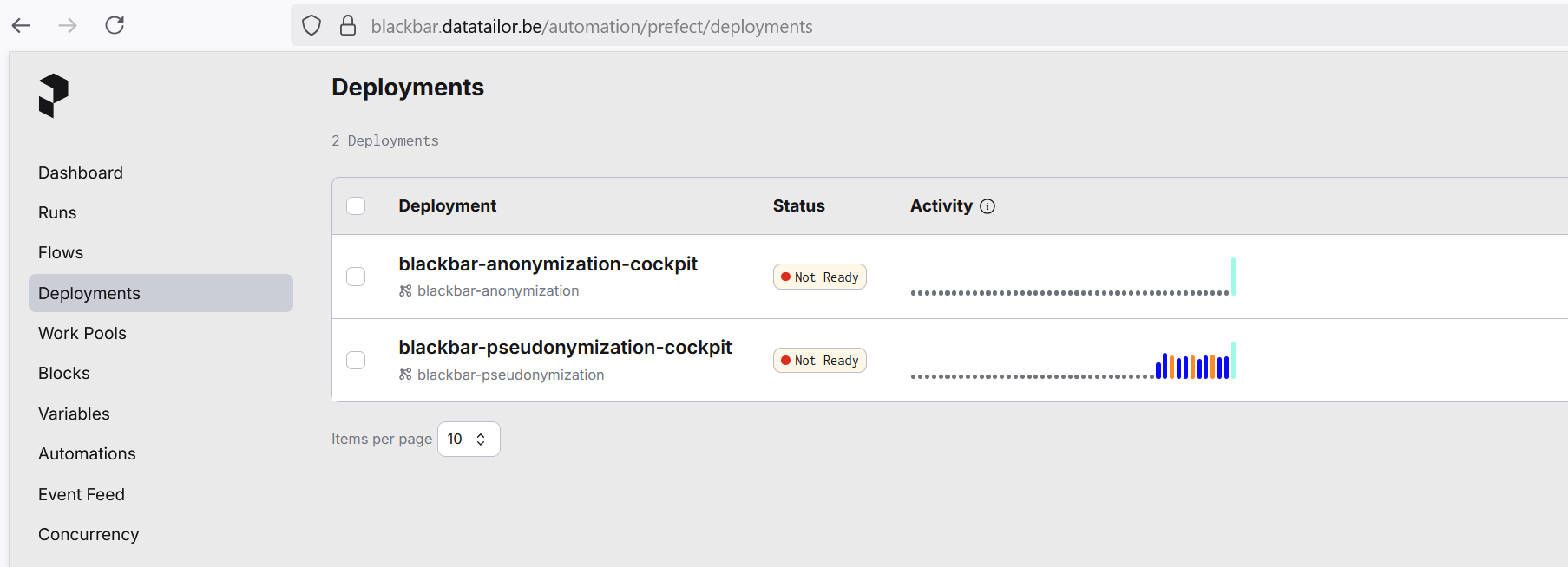
In order to facilitate the deployment of the daily automation of incoming texts, 2 Docker images are provided wich run the anonymization and pseudonymization on your own Docker infrastructure while the monitoring of the logs of these anonymization/pseudonymization runs can be followed up on Prefect.
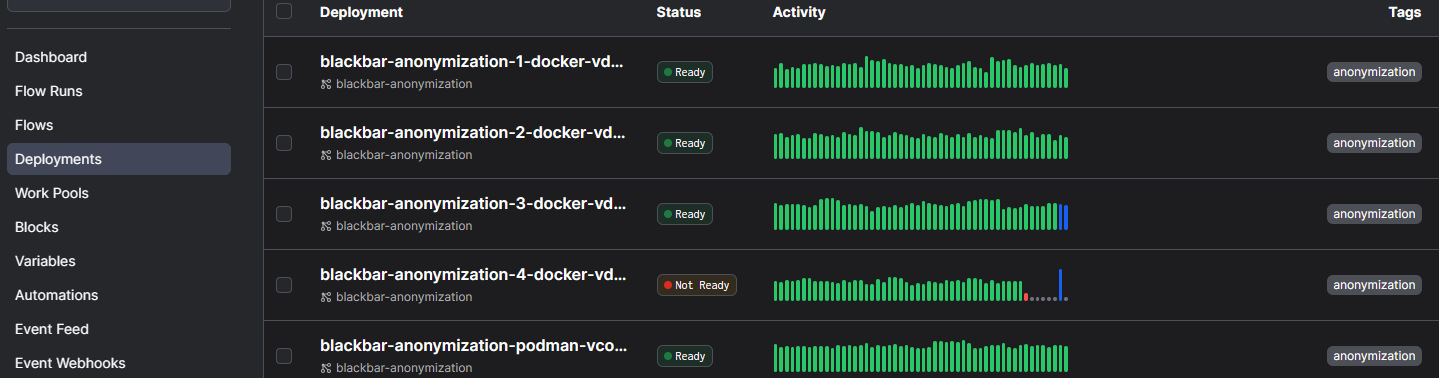
The anonymization/pseudonymization can be automated where the anonymization gets documents for which we need to find and detect the entities, it stores these, updates the status field in the document table. The pseudonymization process takes these detected enities and replaces these with fake values and stores the results.
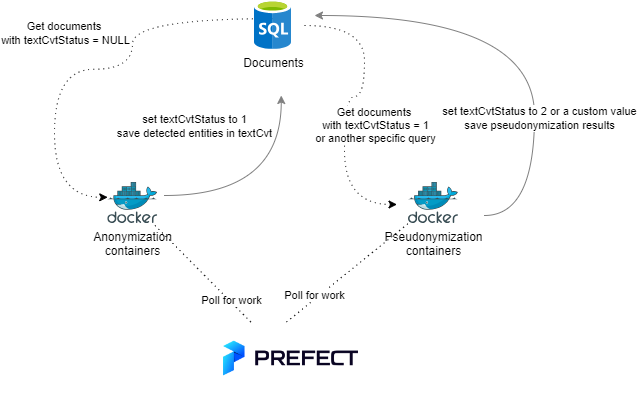
Automated Anonymization
- The following docker image allows to continuously anonymize your texts in the
Documentstable - This is done through Prefect where the code in the container
- gets documents which still need anonymization (textCvtStatus = NULL)
- gets the named entity recognition model from the S3 bucket
- performs the detection of the entities alongside the named entity recognition model and the Smith-Waterman algorithm
- stores the results in the database in columns textCvt and updates the status (textCvtStatus = 1) and the timepoint of the anonymization (textCvtModDate)
- and performs these steps continuously
How
- Pull the docker image and provide your credentials
- Run the container with the environment variables as defined in section containers) + the ones shown below
- This will do the anonymization in sets of 5000 records across 2 CPU cores and will keep on doing the anonymization if new records are found in the given
ANONYMIZATION_QUERYquery. - The model that will be used for that is the one defined in the
BLACKBAR_S3_MODEL_BUCKETandBLACKBAR_S3_MODEL_NAMEenvironment variables. It will download the model from the S3 bucket in order to run it. - If you can run the jobs with more than 1 container, do provide a different
PREFECT_FLOW_NAMEandPREFECT_DEPLOYMENT_NAMEfor each one such that they will show up differently in the Prefect UI.
PREFECT_FLOW_NAME=blackbar-anonymization
PREFECT_DEPLOYMENT_NAME=blackbar-anonymization-podman-dev01x
ANONYMIZATION_QUERY=select TOP {n} ID as doc_id from Data.Document where textCvtStatus is NULL and text is not NULL
ANONYMIZATION_QUERY_CHUNKS=5000
FLOW_PARALLEL_CORES=2
FLOW_SCHEDULE=continuousOnce you launched the container and specified FLOW_SCHEDULE as continuous you can start it in the Prefect UI, if you specify FLOW_SCHEDULE=30 * * * * as a cron expression it will run according to this schedule. If you don’t specify FLOW_SCHEDULE, it will run every hour.
Automated Pseudonymization
- The following docker image allows to continuously pseudonymize texts for which the anonymization was done already
- This is done through Prefect where the code in the container
- gets documents which still need pseudonymization
- performs a replacement of the detected entities
- stores the results in the database tables blackbar_document and blackbar_deid
- stores the original text, the anonymized, the pseudonymised texts
- stores the replacements which were done for reasons of auditing in the database
- all of this is done by patient and data can be stored for a certain project id
- updates the status (textCvtStatus) indicating that the record will no longer be processed
How
- Pull the docker image and provide your credentials
docker pull registry.datatailor.be/blackbar-pseudonymization- Run the container with the following environment variables
docker run --env-file .env registry.datatailor.be/blackbar-pseudonymizationWhere the following set of environment variables shown below have the following meaning.
- Retrieve the top 100 anonymized documents which have status with code 2. Get the patients linked to these documents. For all these patients retrieve all anonymized documents.
- Perform the pseudonymization where the personally identifiable information is replaced based on variants in
nl_BE. The results are saved in tables blackbar_document and blackbar_deid as project id 0 and after this is done, update the textCvtStatus of the Documents table to code 2. - If you specify
FLOW_PARALLEL_CORESto a number higher than 1, it will consume more than one CPU and run the pseudonymization in parallel across the patients. If you don’t specifyFLOW_SCHEDULE, it will run every hour.
PREFECT_FLOW_NAME=blackbar-pseudonymization
PREFECT_DEPLOYMENT_NAME=blackbar-pseudonymization-podman-dev01x
PSEUDONYMIZATION_QUERY=select TOP {n} ID as doc_id, patientId as patient_id, textCvtStatus from Data.Document where textCvtStatus = 1
PSEUDONYMIZATION_QUERY_CHUNKS=100
PSEUDONYMIZATION_LOCALE=nl_BE
PSEUDONYMIZATION_STATUS=2
PSEUDONYMIZATION_PROJECT_ID=0
PSEUDONYMIZATION_FAILURE_STRATEGY=blanks
FLOW_PARALLEL_CORES=2
FLOW_SCHEDULE=continuousOnce you launched the container and specified FLOW_SCHEDULE as continuous you can start it in the Prefect UI, if you specify FLOW_SCHEDULE=30 * * * * as a cron expression it will run according to this schedule. If you don’t specify FLOW_SCHEDULE, it will run every hour.
TipImportant
Note: this assumes all documents of the same patient are already anonymized