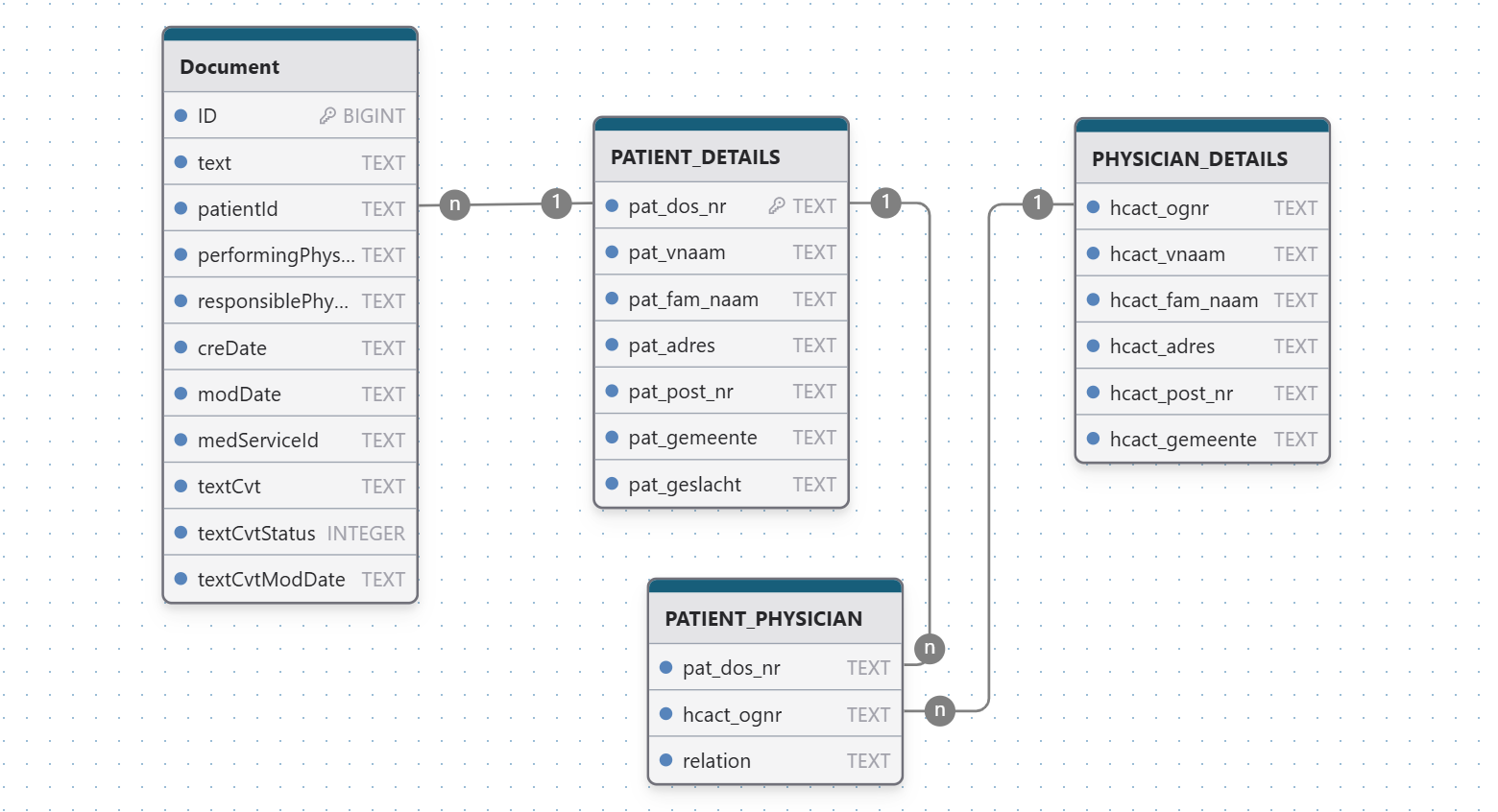
CREATE TABLE "PATIENT_DETAILS" (
"pat_dos_nr" VARCHAR(50) NOT NULL,
"pat_vnaam" VARCHAR(100),
"pat_fam_naam" VARCHAR(100),
"pat_adres" VARCHAR(250),
"pat_post_nr" VARCHAR(10),
"pat_gemeente" VARCHAR(100),
"pat_geslacht" VARCHAR(10),
PRIMARY KEY("pat_dos_nr")
);
CREATE TABLE "PHYSICIAN_DETAILS" (
"hcact_ognr" VARCHAR(50) NOT NULL,
"hcact_vnaam" VARCHAR(100),
"hcact_fam_naam" VARCHAR(100),
"hcact_adres" VARCHAR(250),
"hcact_post_nr" VARCHAR(10),
"hcact_gemeente" VARCHAR(100),
PRIMARY KEY("hcact_ognr")
);
CREATE TABLE "PATIENT_PHYSICIAN" (
"pat_dos_nr" VARCHAR(50) NOT NULL,
"hcact_ognr" VARCHAR(50) NOT NULL,
"relation" VARCHAR(100),
FOREIGN KEY("pat_dos_nr") REFERENCES "PATIENT_DETAILS"("pat_dos_nr"),
FOREIGN KEY("hcact_ognr") REFERENCES "PHYSICIAN_DETAILS"("hcact_ognr")
);
CREATE TABLE "Document" (
"ID" BIGINT NOT NULL UNIQUE,
"text" LONGVARCHAR,
"patientId" VARCHAR(50),
"performingPhysicianId" VARCHAR(200),
"responsiblePhysicianId" VARCHAR(200),
"creDate" TIMESTAMP,
"modDate" TIMESTAMP,
"medServiceId" VARCHAR(200),
"textCvt" LONGVARCHAR,
"textCvtStatus" INTEGER,
"textCvtModDate" TIMESTAMP,
PRIMARY KEY("ID"),
FOREIGN KEY("patientId") REFERENCES "PATIENT_DETAILS"("pat_dos_nr")
);
CREATE INDEX idx_Document_textCvtStatus ON "Document"("textCvtStatus");Database
In order to be able to use the application in order to anonymize and pseudonymize texts of health records, you will need a database which contains these texts.
The database which you can use for this is a relational database. The project has been set up with the use of InterSystems IRIS in mind but it can be any SQL database (MS SQL Server, MariaDB, MySQL, PostgreSQL). A test database can be provided in SQLite with example data.
Anonymization
Your database should have a specific structure with the following information in order to perform the anonymization
PATIENT_DETAILS: records with and id of the patient alongside his/her name/address/gender. The gender is used for gender-specific pseudonymization and can have values ‘male’, ‘M’, ‘female’, ‘F’ or it can be missing or ‘X’.PHYSICIAN_DETAILS: records with and id of the physician/doctor alongside his/her name/addressPATIENT_PHYSICIAN:- records indicating the patient had a relation with a physician (e.g. was treated by, is his personal doctor, fysiotherapist, oncologist, paediatrician, dentist, …).
- this data should contain one row for a combination of patient/physician if you know they are in contact. E.g. put here the medical General Practitioner of a patient.
- these links between patient and physicians are the core way of enabling the Smith-Waterman lookup alongside to improve the named entity recognition detections
Document: health care records with plain texts with a document id, the text and- the patientId which is the same as PATIENT_DETAILS.pat_dos_nr, the name of the performing and responsible physician, when the records was created or updated, optionally the medServiceId indicating a typical group of services which would generate different types of texts.
- textCvt/textCvtStatus/textCvtModDate which store the anonymized text as well as the exact location of the detected personally identifiable information in the texts
- make sure you set an index on Document.textCvtStatus and on Document.patientId
The SQL syntax might be a bit different depending on the database where this is implemented. See the notes 2.
TipAccess rights
The tables PATIENT_DETAILS, PHYSICIAN_DETAILS, PATIENT_PHYSICIAN can be read-only or can be implemented as views in your database. The database user which connects to project blackbar should be allowed to read data from the Document table and should be able to write data to the columns textCvt, textCvtStatus, textCvtModDate.
Pseudonymization
The following 2 pseudonymization tables allow you to store the pseudonymized text records. It allows to store the anonymized and pseudonymized text in table blackbar_document. This pseudonymized text can be different for each project_id depending on the chosen pseudonymization settings. The mapping between the original chunks of text and the replacement is stored in table blackbar_deid.
TipBy patient
The replacement of the entities between the original text chunks and the replaced text chunks is kept for reasons of traceability. The pseudonymization is done by patient such that the replacement is as consistent as possible across all the documents of the same patient.
CREATE TABLE "blackbar_document" (
"doc_id" BIGINT NOT NULL,
"project_id" INTEGER NOT NULL DEFAULT 0,
"creation_date" TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
"patient_id" VARCHAR(50) NOT NULL,
"text" LONGVARCHAR,
"text_anonymized" LONGVARCHAR,
"text_pseudonymized" LONGVARCHAR,
"blackbar_model" VARCHAR(200),
"blackbar_entities" LONGVARCHAR,
"blackbar_options" LONGVARCHAR,
PRIMARY KEY ("doc_id", "project_id")
);
CREATE TABLE "blackbar_deid" (
"deid" BIGINT AUTO_INCREMENT PRIMARY KEY,
"project_id" INTEGER NOT NULL DEFAULT 0,
"patient_id" VARCHAR(50) NOT NULL,
"entity_type" VARCHAR(100) NOT NULL,
"entity_text" VARCHAR(4000) NOT NULL,
"entity_text_replacement" VARCHAR(4000) NOT NULL,
"blackbar_comment" LONGVARCHAR
);Make sure you set the following indexes to speed up internal processes.
CREATE INDEX idx_blackbar_document_doc_id ON "blackbar_document"("doc_id");
CREATE INDEX idx_blackbar_document_patient_id ON "blackbar_document"("patient_id");
CREATE INDEX idx_blackbar_document_project_id ON "blackbar_document"("project_id");
CREATE INDEX idx_blackbar_deid_patient_id ON "blackbar_deid"("patient_id");
CREATE INDEX idx_blackbar_deid_project_id ON "blackbar_deid"("project_id");
CREATE INDEX idx_blackbar_deid_patient_id_project_id ON "blackbar_deid"("patient_id", "project_id");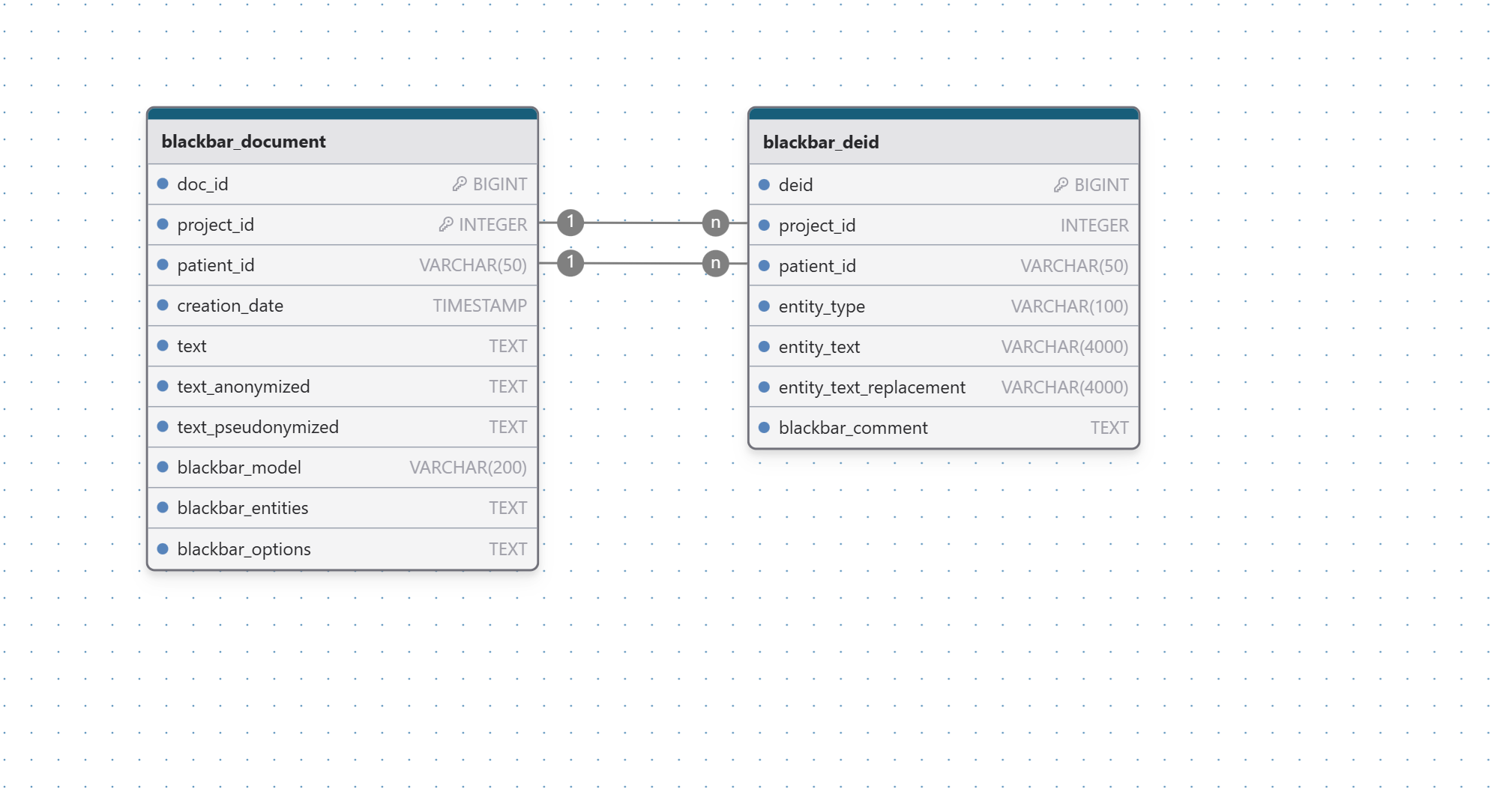
External detection
If you have an external detection system to detect PII information, you can plug in the detected PII entities and texts for a document in the following table. The blackbar processes will pick up these if present in the flows by looking these up with an simple lookup or with Smith-Waterman.
Note that the doc_id should correspond to the ID field in the ´Document´ table. In entity_type you provide a tag from the list of possible tags as defined here. The entity_text is e.g. the detected name/address/… . Fields entity_from and entity_to are optional in case the LLM can not indicate the exact position in the text where it found these.
CREATE TABLE "blackbar_pii_external" (
"doc_id" BIGINT NOT NULL,
"model" VARCHAR(50) NOT NULL DEFAULT 'external',
"entity_type" VARCHAR(100) NOT NULL,
"entity_text" VARCHAR(4000) NOT NULL,
"entity_from" INTEGER DEFAULT NULL,
"entity_to" INTEGER DEFAULT NULL,
"entity_lookup" VARCHAR(25) DEFAULT 'exact',
"entity_lookup_similarity" REAL DEFAULT 1,
"external_comment" LONGVARCHAR DEFAULT NULL,
"creation_date" TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY ("doc_id", "model", "entity_type", "entity_text", "entity_from", "entity_to")
);
CREATE INDEX idx_blackbar_pii_external_doc_id ON "blackbar_pii_external"("doc_id");
CREATE INDEX idx_blackbar_pii_external_model ON "blackbar_pii_external"("model");Notes for database variants
- If you are setting this up on an SQL Server
- you will need to replace TIMESTAMP with DATETIME
- you will need to replace LONGVARCHAR with TEXT
- column blackbar_deid.deid should be of type BIGINT IDENTITY(1, 1) PRIMARY KEY
- If you are setting this up on MariaDB or MySQL
- make sure you don’t quote the column names
- you will need to replace LONGVARCHAR with TEXT
- If you are setting this up on PostgreSQL
- you will need to replace LONGVARCHAR with TEXT
- column blackbar_deid.deid should be of type BIGSERIAL NOT NULL PRIMARY KEY
- make sure the table names are lowercased
- make sure to keep the column names as is (Postgres is case-sensitive so make sure to quote the column names in the document table)
- If you are setting this up on SQlite
- you will need to replace LONGVARCHAR with TEXT
- column blackbar_deid.deid should be of type INTEGER PRIMARY KEY AUTOINCREMENT
- The document identifier in Document.ID can be a primary key of type TEXT. If you do that, you should also make sure the field blackbar_document.doc_id is the same type: TEXT as they correspond and similarly for blackbar_external_pii.doc_id.