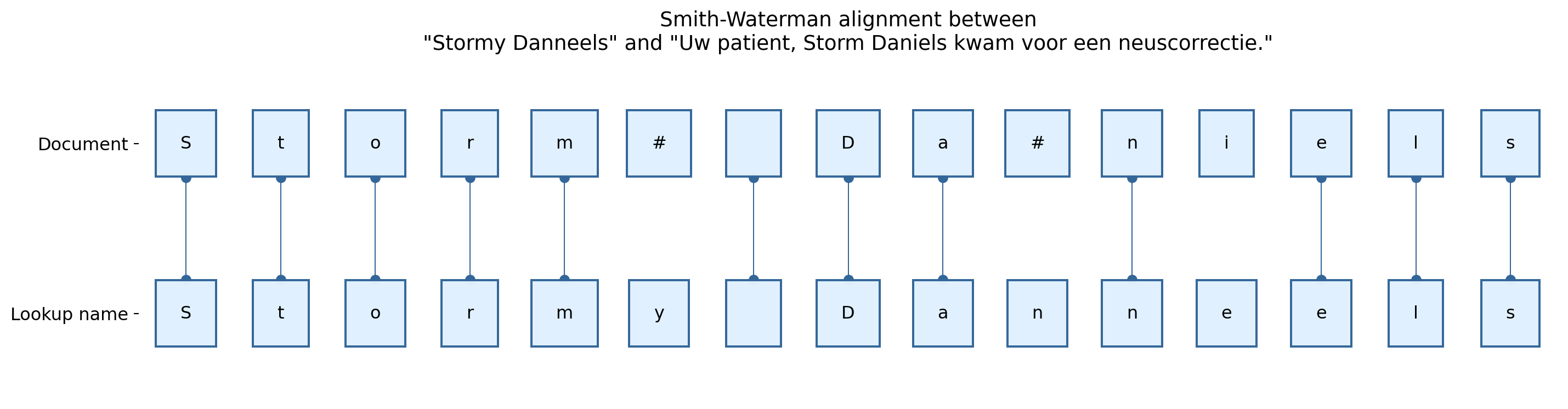
Local alignment between "Stormy Danneels" and "Uw patient, Storm Daniels kwam voor een neuscorrectie.", by the Smith-Waterman algorithm:
S | t | o | r | m | y | | D | a | n | n | e | e | l | s
S | t | o | r | m | # | | D | a | # | n | i | e | l | sAlgorithms
The core algorithms which are used throughout the framework are
- Named Entity Recognition models
- Smith-Waterman local alignment
- Text similarity metrics
- Generative AI models
Named Entity Recognition
Named Entity Recognition is used in order to detect Personally Identifiable Information. You can easily train the following models on your texts
- Convolutional Neural Network (CNN)
- Bidirectional LSTM model (BiLSTM)
- Transformer model (Transformer)
Smith-Waterman
In order to identify known names and addresses and identifiers for a certain document including possible spelling errors or variants, the framework relies on recursive Smith-Waterman local alignment between texts and known names/addresses.
Smith-Waterman allows for typos in the name and is hence suitable for common typing human errors when someone sets up a document. If we have the following text
‘Uw patient, Storm Daniels kwam voor een neuscorrectie.’ and we know that the text is about a patient called ‘Stormy Danneels’.
We can lookup that name and assign a positive score if letters can be aligned and a negative score if letters are a gap or misaligned. In this way the algorithm constructs a 2D matrix where of scores. The algorithm takes the highest score and backtracks to the start of the matrix to find the local alignment. If we do that recursively, we can find several times the same name or address.
Here you can see the local alignment matrix - zoomed in such that we can see the alignment path more clearly with the matches alongside the diagonal and the gaps and mismatches which are not alongside the diagonal.
Local alignment between "Storm Daniels" and "Stormy Danneels", by the Smith-Waterman algorithm:
S | t | o | r | m | # | | D | a | # | n | i | e | l | s
S | t | o | r | m | y | | D | a | n | n | e | e | l | s
Pseudonymization
The pseudonymization is locale-specific where suitable replacements are found by patient such that the data stays consistent by patient.
- The python package blackbar-py includes pseudo names and adresses for locales in Dutch, French, English, German, Spanish and Italian namely: ‘nl_BE’ / ‘fr_BE’ / ‘nl_NL’ / ‘fr_FR’ / ‘en_GB’ / ‘de_DE’ / ‘de_LU’ / ‘es_ES’ / ‘it_IT’
- The pseudonymization allows gender-specific replacements based on the gender of the patient
- The pseudonymization happens by entity type
- and performs a lot of regular expressions to handle the most occuring patterns for each entity (Name / Address / Date / Birthdate / Profession / Contactdetails / Organization / ID of patient / ID of register number)
- more complex patterns are handled by a Large Language model where prompts are set up for finding suitable replacements or by a strategy where similarly sounding entities with enough dissimilarities are found
- Dates are parsed and shifted with a specified set of days/months/weeks/years
- Readability is maintained (e.g. use of newlines, spaces)
Generative AI
For pseudonymization which is not handled by the elements listed above (e.g. +/- 0.3% of the entities), the setup allows to pseudonymize using Generative AI which is considerable more compute-intensive.
- In the current setup the 4B quantised gemma-3 model is used namely:
- gemma-3-4b-it-qat-q4_0-gguf
- available at https://huggingface.co/google/gemma-3-4b-it-qat-q4_0-gguf
- The model is included in the pseudonymization docker container, runs offline (no internet access needed / nor API calls are done) and strikes a balance between speed of pseudonymization on CPU’s and how good the generative AI model is.
- When using the llm as backup failure strategy, you are subject to the Gemma terms of use as described at https://ai.google.dev/gemma/terms, which basically allow to use the generated pseudonymized output at your discretion
- The prompts which are used to do the pseudonymization can be requested
- If the llm is used for the pseudonymization, this is shown in the blackbar_comment column of table blackbar_deid.