UDPipe Introduction
This repository contains an R package which is an Rcpp wrapper around the UDPipe C++ library (http://ufal.mff.cuni.cz/udpipe, https://github.com/ufal/udpipe).
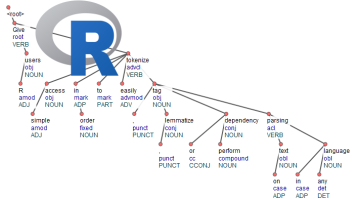
- UDPipe provides language-agnostic tokenization, tagging, lemmatization and dependency parsing of raw text, which is an essential part in natural language processing.
- The techniques used are explained in detail in the paper: "Tokenizing, POS Tagging, Lemmatizing and Parsing UD 2.0 with UDPipe", available at http://ufal.mff.cuni.cz/~straka/papers/2017-conll_udpipe.pdf. In that paper, you'll also find accuracies on different languages and process flow speed (measured in words per second).
General
The udpipe R package was designed with the following things in mind when building the Rcpp wrapper around the UDPipe C++ library:
- Give R users simple access in order to easily tokenize, tag, lemmatize or perform dependency parsing on text in any language
- Provide easy access to pre-trained annotation models
- Allow R users to easily construct your own annotation model based on data in CONLL-U format as provided in more than 100 treebanks available at http://universaldependencies.org/#ud-treebanks
- Don't rely on Python or Java so that R users can easily install this package without configuration hassle
- No external R package dependencies except the strict necessary (Rcpp and data.table, no tidyverse)
Installation & License
The package is available under the Mozilla Public License Version 2.0. Installation can be done as follows. Please visit the package documentation at https://bnosac.github.io/udpipe/en and look at the R package vignettes for further details.
install.packages("udpipe")
vignette("udpipe-tryitout", package = "udpipe")
vignette("udpipe-annotation", package = "udpipe")
vignette("udpipe-universe", package = "udpipe")
vignette("udpipe-usecase-postagging-lemmatisation", package = "udpipe")
# An overview of keyword extraction techniques: https://bnosac.github.io/udpipe/docs/doc7.html
vignette("udpipe-usecase-topicmodelling", package = "udpipe")
vignette("udpipe-parallel", package = "udpipe")
vignette("udpipe-train", package = "udpipe")
Example
Currently the package allows you to do tokenisation, tagging, lemmatization and dependency parsing with one convenient function called udpipe
library(udpipe)
udmodel <- udpipe_download_model(language = "dutch")
udmodel
language file_model
dutch-alpino C:/Users/Jan/Dropbox/Work/RForgeBNOSAC/BNOSAC/udpipe/dutch-alpino-ud-2.5-191206.udpipe
x <- udpipe(x = "Ik ging op reis en ik nam mee: mijn laptop, mijn zonnebril en goed humeur.",
object = udmodel)
x
doc_id paragraph_id sentence_id start end term_id token_id token lemma upos xpos feats head_token_id dep_rel misc
doc1 1 1 1 2 1 1 Ik ik PRON VNW|pers|pron|nomin|vol|1|ev Case=Nom|Person=1|PronType=Prs 2 nsubj <NA>
doc1 1 1 4 7 2 2 ging gaan VERB WW|pv|verl|ev Number=Sing|Tense=Past|VerbForm=Fin 0 root <NA>
doc1 1 1 9 10 3 3 op op ADP VZ|init <NA> 4 case <NA>
doc1 1 1 12 15 4 4 reis reis NOUN N|soort|ev|basis|zijd|stan Gender=Com|Number=Sing 2 obl <NA>
doc1 1 1 17 18 5 5 en en CCONJ VG|neven <NA> 7 cc <NA>
doc1 1 1 20 21 6 6 ik ik PRON VNW|pers|pron|nomin|vol|1|ev Case=Nom|Person=1|PronType=Prs 7 nsubj <NA>
doc1 1 1 23 25 7 7 nam nemen VERB WW|pv|verl|ev Number=Sing|Tense=Past|VerbForm=Fin 2 conj <NA>
doc1 1 1 27 29 8 8 mee mee ADP VZ|fin <NA> 7 compound:prt SpaceAfter=No
doc1 1 1 30 30 9 9 : : PUNCT LET <NA> 7 punct <NA>
...
Pre-trained models
Pre-trained models build on Universal Dependencies treebanks are made available for more than 65 languages based on 101 treebanks, namely:
afrikaans-afribooms, ancient_greek-perseus, ancient_greek-proiel, arabic-padt, armenian-armtdp, basque-bdt, belarusian-hse, bulgarian-btb, buryat-bdt, catalan-ancora, chinese-gsd, chinese-gsdsimp, classical_chinese-kyoto, coptic-scriptorium, croatian-set, czech-cac, czech-cltt, czech-fictree, czech-pdt, danish-ddt, dutch-alpino, dutch-lassysmall, english-ewt, english-gum, english-lines, english-partut, estonian-edt, estonian-ewt, finnish-ftb, finnish-tdt, french-gsd, french-partut, french-sequoia, french-spoken, galician-ctg, galician-treegal, german-gsd, german-hdt, gothic-proiel, greek-gdt, hebrew-htb, hindi-hdtb, hungarian-szeged, indonesian-gsd, irish-idt, italian-isdt, italian-partut, italian-postwita, italian-twittiro, italian-vit, japanese-gsd, kazakh-ktb, korean-gsd, korean-kaist, kurmanji-mg, latin-ittb, latin-perseus, latin-proiel, latvian-lvtb, lithuanian-alksnis, lithuanian-hse, maltese-mudt, marathi-ufal, north_sami-giella, norwegian-bokmaal, norwegian-nynorsk, norwegian-nynorsklia, old_church_slavonic-proiel, old_french-srcmf, old_russian-torot, persian-seraji, polish-lfg, polish-pdb, polish-sz, portuguese-bosque, portuguese-br, portuguese-gsd, romanian-nonstandard, romanian-rrt, russian-gsd, russian-syntagrus, russian-taiga, sanskrit-ufal, scottish_gaelic-arcosg, serbian-set, slovak-snk, slovenian-ssj, slovenian-sst, spanish-ancora, spanish-gsd, swedish-lines, swedish-talbanken, tamil-ttb, telugu-mtg, turkish-imst, ukrainian-iu, upper_sorbian-ufal, urdu-udtb, uyghur-udt, vietnamese-vtb, wolof-wtb.
These have been made available easily to users of the package by using udpipe_download_model
How good are these models?
- Accuracy statistics of models provided by the UDPipe authors which you download with udpipe_download_model from the default repository are available at this link.
- Accuracy statistics of models trained using this R package which you download with udpipe_download_model from the bnosac/udpipe.models.ud repository are available at https://github.com/bnosac/udpipe.models.ud.
- For a comparison between UDPipe and spaCy visit https://github.com/jwijffels/udpipe-spacy-comparison
Train your own models based on CONLL-U data
The package also allows you to build your own annotation model. For this, you need to provide data in CONLL-U format. These are provided for many languages at http://universaldependencies.org/#ud-treebanks, mostly under the CC-BY-SA license. How this is done is detailed in the package vignette.
vignette("udpipe-train", package = "udpipe")
Support in text mining
Need support in text mining? Contact BNOSAC: http://www.bnosac.be